


1.CTR介绍
点击率(click-through rate, CTR)是互联网公司进行流量分配的核心依据之一。比如互联网广告平台,为了精细化权衡和保障用户、广告、平台三方的利益,准确的CTR预估是不可或缺的。CTR预估技术从传统的逻辑回归,到近两年大火的深度学习,新的算法层出不穷:DeepFM, NFM, DIN, AFM, DCN……
从FM及其与神经网络的结合出发,能够迅速贯穿很多深度学习CTR预估网络的思路,从而更好地理解和应用模型。
2.CTR深度模型的推导思路
从原理上进行推导深度CTR预估模型,达到知其然也知其所以然的目的。
核心思路:通过设计网络结构进行组合特征的挖掘。
具体来说有两条:
- 从FM开始推演其在深度学习上的各种推广(下图红线)
- 从embedding+MLP自身的演进特点结合CTR预估本身的业务场景进行推演(下图黑线)
便于理解,我们简化了数据案例——只考虑离散特征数据的建模,以分析不同神经网络在处理相同业务问题时的不同思路。
3.FM:降维思路下的特征二阶组合
CTR预估本质是一个二分类问题。以移动端展示广告推荐为例,依据日志中的用户侧的信息(年龄、性别、婚否,手机上安装的app列表)、广告侧的信息(标题、类别、内容等)、上下文侧信息(渠道id等),去建模预测用户是否会点击该广告。
FM出现之前的传统的处理方法是人工特征工程加上线性模型(如逻辑回归Logistic Regression)。为了提高模型效果,关键就是特征工程,即是找到用户点击行为背后隐含的特征。如男性、大学生用户往往会点击游戏类广告,因此"男性且是大学生且是游戏类"的特征组合就是一个关键特征。但这本质仍是线性模型,其假设函数表示成内积形式一般为:
![]()
![]()
其中x为特征向量,w为权重向量,σ()为sigmoid函数。
但是人工进行特征组合通常会存在诸多困难,如维度灾难、特征难以被识别、特征难以组合等。为了让模型自动地考虑特征之间的二阶组合信息,线性模型推广为二阶多项式(2d−Polynomial)模型:
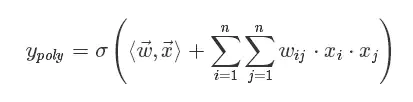
其实就是对特征向量两两点乘构成新特征(离散化之后其实就是"且"操作),并对每个新特征分配独立的权重,通过机器学习来自动获得这些权重。矩阵形式为:
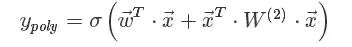
其中W2为二阶特征组合的权重矩阵,是对称矩阵。而这个矩阵参数非常多,为O(n2)。为了降低该矩阵的维度,可以将其因子分解(
FactorizationFactorization)为两个低维(比如n∗k)矩阵的相乘。则此时W2矩阵的参数就大幅降低,为O(nk)。公式如下:
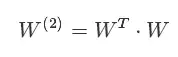
这就是Rendle等在2010年提出的因子分解机(Factorization Machines,FM)。FM的矩阵形式公式如下:
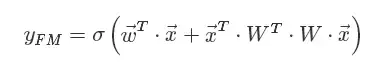
写成内积形式:
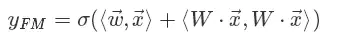
由于:
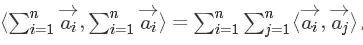
将上式改写成求和式形式:
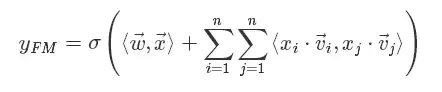
其中vi向量是矩阵W的第i列。为了去除重复项与特征平方项,上式可以进一步改写成更为常见的FM公式:
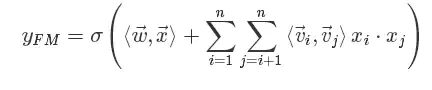
对比二阶多项式模型,FM模型中特征两两相乘(组合)的权重是相互不独立的,它是一种参数较少但表达力强的模型。
4.从神经网络的视角看FM:嵌入后再进行内积
我们观察FM公式的矩阵内积形式:
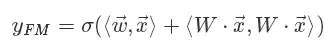
发现W*x部分就是将离散系数特征通过矩阵乘法降维成一个低维稠密向量。这个过程对神经网络来说就叫做嵌入(embedding)。所以用神经网络视角来看:
- FM首先是对离散特征进行嵌入。
- 之后通过对嵌入后的稠密向量进行内积来进行二阶特征组合。
- 最后再与线性模型的结果求和进而得到预估点击率。
其示意图如下。清晰起见,我们绘制的是神经网络计算图而不是网络结构图——在网络结构图中增加了权重W的位置。
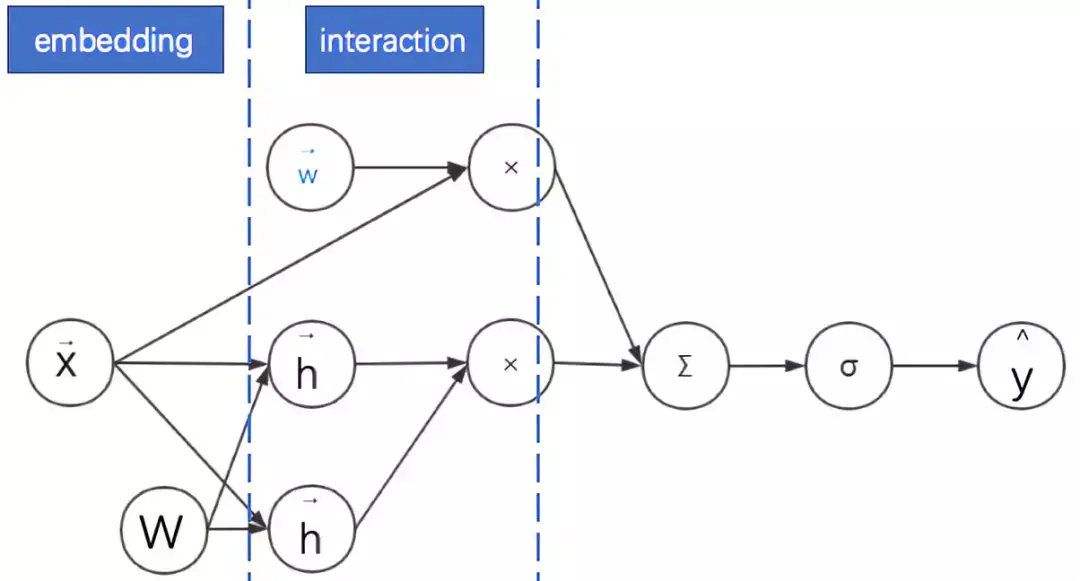
5.FM的实际应用:考虑特征领域信息
广告点击率预估模型中的特征以分领域的离散特征为主,如:广告类别、用户职业、手机APP列表等。由于连续特征比较好处理,为了简化起见,本文只考虑同时存在不同领域的离散特征的情形。处理离散特征的常见方法是通过one-hot编码转换为一系列二值特征向量。
然后将这些高维稀疏特征通过嵌入(embedding)转换为低维连续特征。前面已经说明FM中间的一个核心步骤就是嵌入,但这个嵌入过程没有考虑领域信息。这使得同领域内的特征也被当做不同领域特征进行两两组合了。
其实可以将特征具有领域关系的特点作为先验知识加入到神经网络的设计中去:同领域的特征嵌入后直接求和作为一个整体嵌入向量,进而与其他领域的整体嵌入向量进行两两组合。而这个先嵌入后求和的过程,就是一个单领域的小离散特征向量乘以矩阵的过程。
此时FM的过程变为:对不同领域的离散特征分别进行嵌入,之后再进行二阶特征的向量内积。其计算图图如下所示:
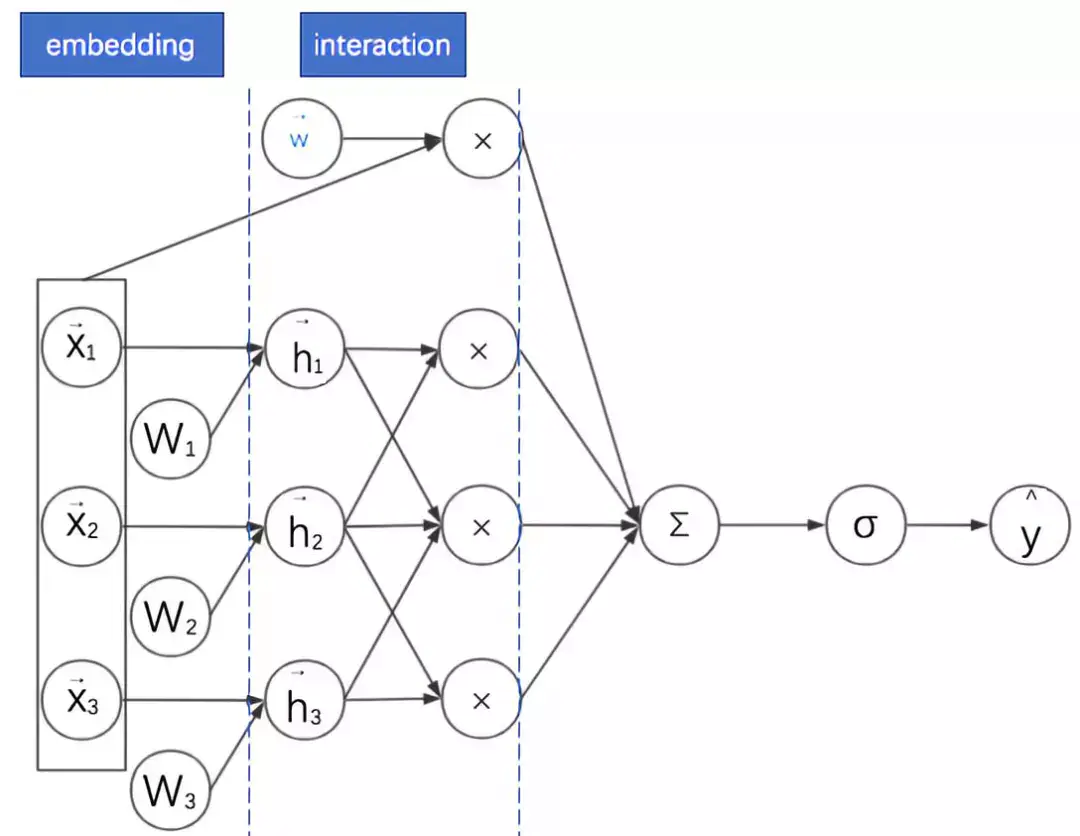
这样考虑其实是给FM增加了一个正则:考虑了领域内的信息的相似性。而且还有一个附加的好处,这些嵌入后的同领域特征可以拼接起来作为更深的神经网络的输入,达到降维的目的。接下来我们将反复看到这种处理方式。
此处需要注意,这与"基于领域的因子分解机"(Field-aware Factorization Machines,FFM)有区别。FFM也是FM的另一种变体,也考虑了领域信息。但其不同点是同一个特征与不同领域进行特征组合时,其对应的嵌入向量是不同的。本文不考虑FFM的作用机制。
经过这些改进的FM终究还是浅层网络,它的表现力仍然有限。为了增加模型的表现力(model capacity),一个自然的想法就是将该浅层网络不断"深化。"
6.embedding+MLP:CTR深度学习模型的通用框架
embedding+MLP是对于分领域离散特征进行深度学习CTR预估的通用框架。深度学习在特征组合挖掘(特征学习)方面具有很大的优势。比如以CNN为代表的深度网络主要用于图像、语音等稠密特征上的学习,以W2V、RNN为代表的深度网络主要用于文本的同质化、序列化高维稀疏特征的学习。CTR预估的主要场景是对离散且有具体领域的特征进行学习,所以其深度网络结构也不同于CNN与RNN。
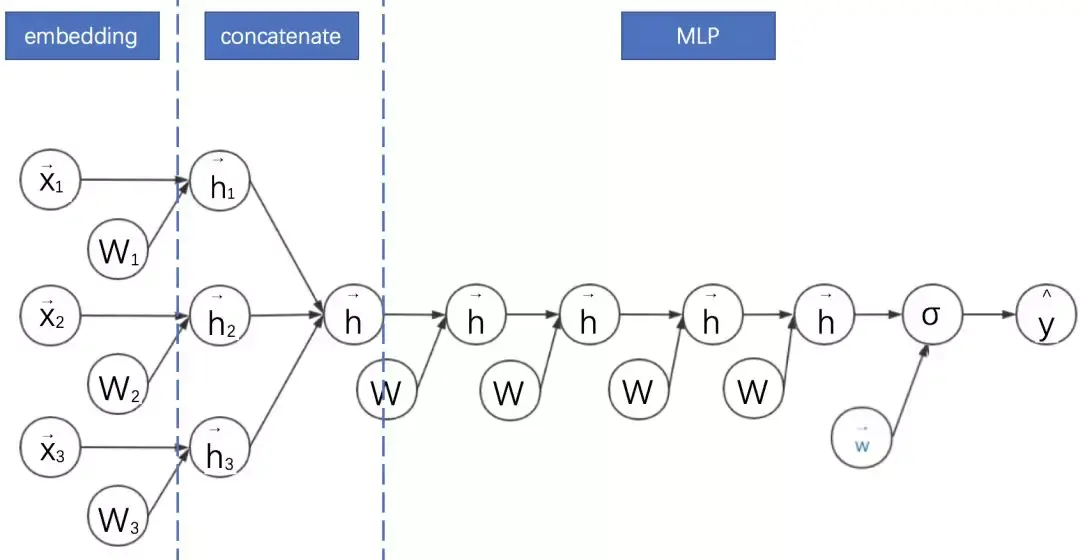
embedding+MLP的过程如下:
1. 对不同领域的one-hot特征进行嵌入(embedding),使其降维成低维度稠密特征。
2. 然后将这些特征向量拼接(concatenate)成一个隐含层。
3. 之后再不断堆叠全连接层,也就是多层感知机(Multilayer Perceptron, MLP,有时也叫作前馈神经网络)。
4. 最终输出预测的点击率。
其示意图如下:
embedding+MLP的缺点是只学习高阶特征组合,对于低阶或者手动的特征组合不够兼容,而且参数较多,学习较困难。本文今天主要讲到此,实现了由FM到深度神经网络表示的转变,后续会继续发文讲解改进的其他模型。
文章来源于网络,如若侵权,请联系站长删除。
本站承接各类商务合作,如有合作需求,请联系我们。
相关推荐
-
pgc是什么意思(UGC、PGC、OGC、PPC分享对比)
名词解释 UGC,User Generated Content,指用户原创的内容,也就是普通大众创造的内容。一般不参与平台分成,源于个人爱好,目的是为了展现自我。比如微博、朋友圈、抖音之类。 PGC,Professionally-generated Co...
-
什么是跨境电商进口(零售进口税收政策解答)
中国青年网北京8月21日电 据海关总署消息,随着经济全球化的高度发展以及互联网的普及,跨境电子商务与人们联系愈发紧密,消费者在指尖上可以轻松地实现“买全球”。那么跨境电商进口有哪些模式?我们常见的“保税仓...
-
搞活动补差价是怎么补的(补差价是怎么补的)
买完东西还能赚差价? 能退真金白银的价保服务 网购商品刚到手,拆箱整准备给个好评,却发现店铺竟将商品价格下调了几块甚至几十块?这样的经历想必不少热衷电商购物的网友都遇到过,尤其是在618、双11等时间节点...
-
全球外贸网上采购平台有哪些(国际采购平台有哪些)
B2B平台大家都知道,是方便商家进货的平台,便宜实惠。但是如果你不是商家,也是可以通过在B2B平台买些日常生活中的东西,价格比一些电商便宜多了。而且现在的的B2B平台,大多数可以一键代发,不需要大量购买即可...
-
新人如何做好直播(新手如何从0开始做直播)
第一步:从总部布局直播 从总部开始行动,选择直播平台,尝试直播2-3场,观测直播效果 第二步:小规模门店试水 如果预选的直播平台符合公司对于直播的布局,以某个区域为试点,邀请5-10家门店直播,培训并观测直...
-
电子商务怎么赚钱(电商怎么做比较赚钱)
当说到电商红利这个词时,很多人可能会觉得,这都什么年代了,怎么可能还会有电商红利。这句话的出发点是站在既有的淘系老平台来看的,淘系的红利确实没有了,但是像抖店、拼多多等还没有完全成熟的电商平台,依...
-
获取京东e卡(一步搞定)
导语:京东e卡是一种便捷的购物支付方式,只需要一步就可以获取。它可以用来在京东商城购买各种商品,支持多种支付方式,支付过程快捷安全,支付成功后可以立即使用。它不仅可以用来购买商品,还可以用来充值手机...
-
怎么开电商公司(做电商开什么公司比较好)
随着消费者消费习惯的改变,向线上商城转型已经是企业未来能够持续发展的必要因素。但是,如何向线上转型,如何真正地做好电商呢? 就让小来来分析一下自己总结的经验吧! 中小企业如何做电商 1. 寻找合适的电商...
-
直播冷启动是什么意思(新人主播如何度过冷启动期)
都是新号开播,难题也不少,因为之前都不是专业的互联网电商从业者,需要自己慢慢学,但机会不等人,错过风口就遗失先机了。 小商家小品牌,知名度不足;新号开播场观人数少;商品的初始销量低,用户信任还未建立...
-
海外仓一件代发怎么操作(怎样做一件代发的流程呢)
随着跨境电子商务的快速发展,对物流支撑的要求不断提高,对便捷高效的境外仓储物流的需求也逐年增加。 海外仓库作为跨境电子商务卖家的重要物流模式,逐渐成为跨境电子商务的标准。 什么是海外仓一件代发? 海外...